개요
Apach kafka를 학습을 통해 배운 개념 및 핵심을 정리해 본다.
카프카 유래
구인/구직 사이트인 '링크드 인'에서 카프카를 개발하게 되었는데 기존 파편화된 데이터 파이프라인의 복잡도를 줄이기 위함이였음.
- 소스 애플리케이션과 타깃 어플리케이션 사이의 디 커플링을 위함.
- 자료구조는 '큐'와 비슷
- 클러스터 환경에서 작동되며 정족수(홀수 3개이상)셋팅 추천
데이터 레이크(data lake) 환경을 만들기 위함이며 이미 SK,삼성,카카오, 네이버 등과 같은 많은 IT 기업에서 사용 중
카프카 특징
1. 높은 처리량
분산 클러스터 및 다중 파티션 기능을 지원하기 때문에 데이터를 병령 처리 가능
2. 확장성
클러스터링 구조를 사용하기 때문에 스케일 아웃(scale out: 서버 추가), 스케일 인(scale in: 서버 제거) 가능
3. 영속성
메시지(토픽)을 파일 형태로 저장하면서 I/O 성능향상을 위한 페이지 캐시(page cache)를 활용하기 때문에 데이터 유실을 방지 할 수 있음
4. 고가용성
크러스터 구성이라 노드(브로커)중 하나에 문제가 생기더라도 나머지 클러스터 내에 존재하는 노드(브로커)가 메시지(클러스터 내 복재)를 이어서 제공해 줌, 관련 설정 'min.insync.replicas' : 2 (최소 2개 이상의 브로커에 데이터가 완전히 복제됨을 의미)
카프카 생태계 모식도

기존 아키텍처
카프카 아키텍쳐
1. 람다 아키텍처
2. 카파 아키텍처
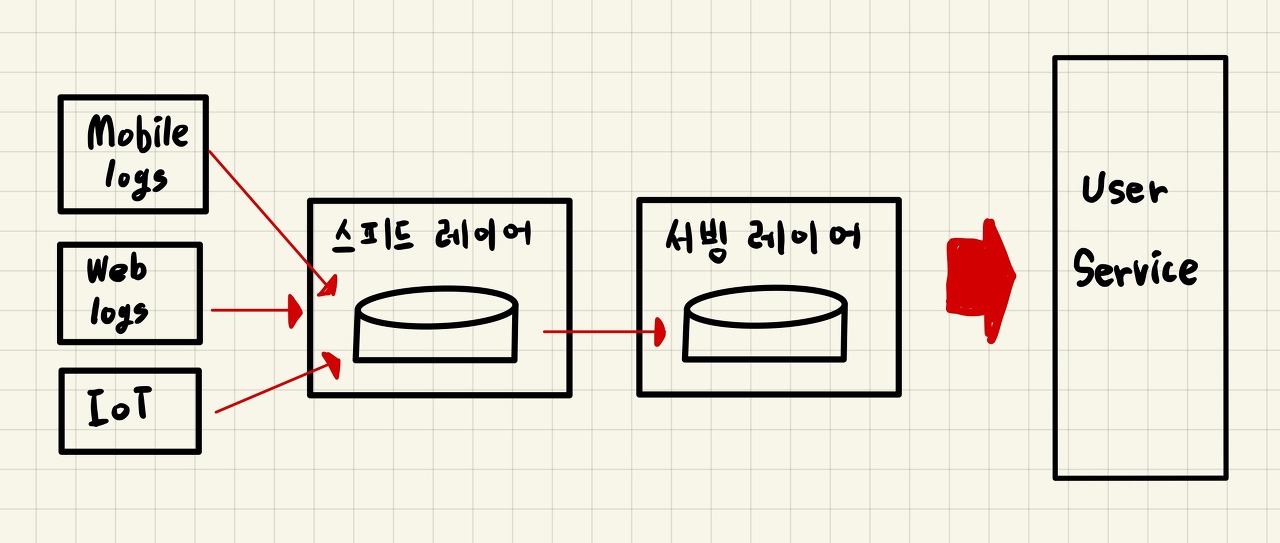
3. 스트리밍 데이터 레이크 아키텍처
참고 문서:
책: 아파치 카프카 애플리케이션 프로그래밍 with 자바 (데브원영)
이미지 출처
반응형
사업자 정보 표시
라울앤알바 | 장수호 | 서울특별시 관악구 봉천로 13나길 58-10, 404호(봉천동) | 사업자 등록번호 : 363-72-00290 | TEL : 010-5790-0933 | Mail : shjang@raulnalba.com | 통신판매신고번호 : 2020-서울관악-0892호 | 사이버몰의 이용약관 바로가기
'Lab > Kafka lab' 카테고리의 다른 글
| 2. apach kafka 설치 방법 정리 (0) | 2023.06.21 |
|---|
